Rooke
Chess web app for beginners with sandbox and vs AI mode
Rooke is a browser based 3D chess app for users to play chess against a custom AI engine or use a sandbox mode. Its differentiator from other chess apps is the visual transparency of the AI: Rooke renders the engine's internal deliberation process in real time with narrative logs and visuals. The goal of this project was to make the AI's thinking tangible essentially turning a normal game into a mini educational experience for newer players.
Architecture
Rooke follows a monolithic, event driven SPA architecture with AI work offloaded to a Web Worker:
| Layer | Responsibility | Tech |
|---|---|---|
| UI | 3D scene rendering, camera controls, UI overlays (sidebar, timers, move history, AI log panel) | Three.js, GSAP, DOM manipulation |
| Game Logic | Board state, move generation, legal move validation, check/checkmate detection, special moves (castling, en passant, etc.) | TypeScript |
| AI Engine | Minimax tree search with alpha beta pruning, quiescence search, move ordering (MVV-LVA), piece square table evaluation | Web Worker (TypeScript) |
| Build / Dev | Bundling, HMR, TypeScript compilation | Vite, PostCSS, Tailwind CSS |
| Production | Static file for deployment | Express.js |
Basic Architecture
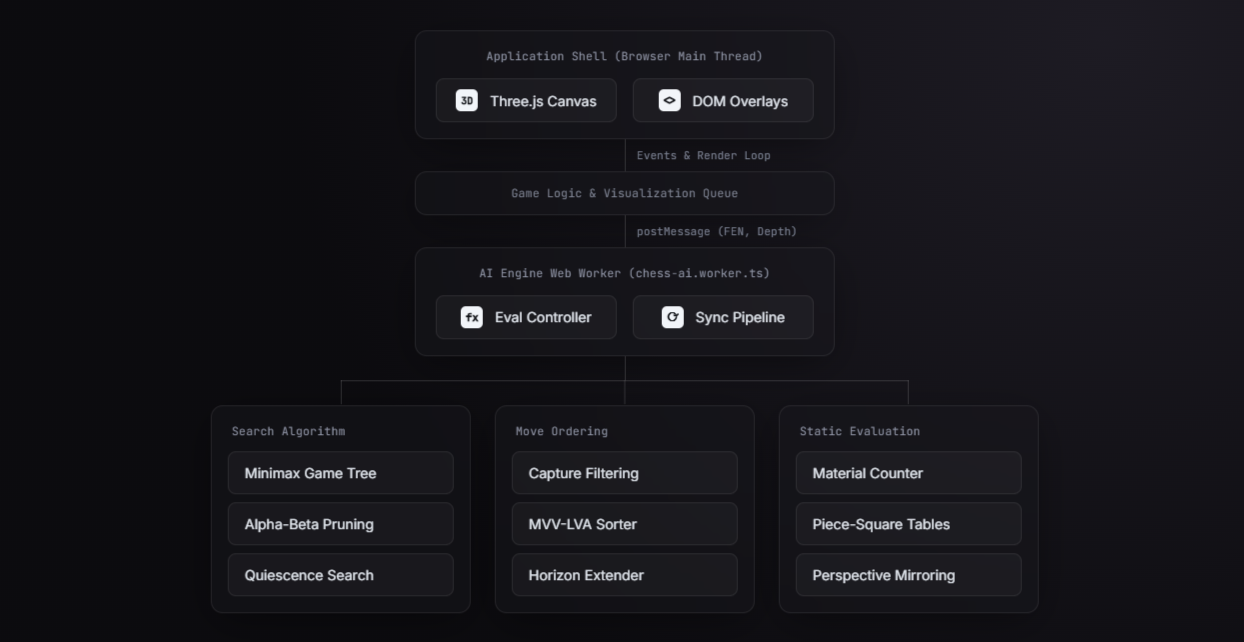
Game Logic & Move Validation
The chess rules engine implements the full FIDE rule set for both move generation and validation.
Move Generation: getPossibleMovesRaw(piece) generates all pseudo legal moves for each piece type. Sliding diagonal pieces (like bishop, rook, queen) use a ray casting pattern that extends in each direction until it hits the board edge or another piece. The addMove helper handles bounds checking and capture detection returning false to stop the ray when a blocking piece is hit:
const addMove = (x: number, z: number) => { if (x < 0 || x >= 8 || z < 0 || z >= 8) return false const target = getPieceAt(x, z) if (target && target.isWhite === piece.isWhite) return false // can't capture your own teams piece moves.push({ x, z }) return !target // continue if square is open -> stop if occupied }
The Special Moves Implemented:
- Castling: Validates five conditions (king/rook haven't moved, path empty, no squares under attack) and handles both kingside (O-O) and queenside (O-O-O).
- En Passant: Tracked using the
lastMoveglobal: if the previous move was a 2 square pawn push by the player and the current pawn is laterally adjacent then the diagonal capture is available. - Pawn Promotion: When a pawn reaches the end of the other players side, a modal pauses the game. The the old pawn's 3D mesh is removed from the game and a new piece replaces it
AI Chess Engine
The engine runs inside a Web Worker in case of any UI freezes during the game and the search. The engine is built on 3 main algorithmic concepts.
1) Board Evaluation: Piece Square Tables
The evaluation function scores any board position as:
Score = Σ(white pieces) (Material + PST) – Σ(black pieces) (Material + PST)
Positive = AI advantage (White) , negative = User advantage (Black). Material values follow the standard chess engine conventions:
| Piece | Value (centipawns) | Meaning |
|---|---|---|
| Pawn | 100 | Baseline unit |
| Knight | 320 | Worth ~3.2 pawns |
| Bishop | 330 | Worth ~3.3 pawns |
| Rook | 500 | Worth 5 pawns |
| Queen | 900 | Worth 9 pawns |
| King | 20,000 | Basically infinite |
On top of material counting, Piece Square Tables (PSTs) add positional awareness. Each piece type has a 64 element lookup table that assigns perks or penalties based on where the piece sits. For example, the knight PST for a knight on d4 (center) gets +20, while a knight on a1 (corner) gets -50
Tables are written from White's perspective (AI). For Black pieces, the index is mirrored (table[63 - i]), flipping the board so Black's "positive squares" are on the Black's side.
Minimax with Alpha Beta Pruning
The search used is a minimax tree search: White tries to maximize the evaluation, Black tries to minimize it, both assuming optimal moves. Alpha beta pruning helps to reduce the search space by tracking 2 bounds:
- α (alpha): the best score the maximizer is guaranteed.
- β (beta): the best score the minimizer is guaranteed.
When β ≤ α, the current branch is pruned:
function minimax(depth: number, alpha: number, beta: number, isMaximizing: boolean) { nodeCount++; if (depth === 0) { return { score: quiescence(alpha, beta, isMaximizing), line: [] }; } const moves = orderMoves(generateMoves(board, color), board); if (isMaximizing) { let maxEval = -Infinity; for (let move of moves) { // Make move const saved = board[move.to]; board[move.to] = board[move.from]; board[move.from] = null; const result = minimax(depth - 1, alpha, beta, false); // Unmake move board[move.from] = board[move.to]; board[move.to] = saved; if (result.score > maxEval) { maxEval = result.score; bestLine = [move, ...result.line]; } alpha = Math.max(alpha, result.score); if (beta <= alpha) break; // β cutoff: prune the remaining moves } return { score: maxEval, line: bestLine }; } // mirrored for minimizing the user (beating them) }
Complexity impact: Without pruning, a depth 3 search with around 30 moves per position would be 30³ = 27,000 nodes. With both good move ordering and alpha beta, the effective branching factor drops to around √30 ≈ 5.5 which reduces the search to around 166 nodes: which is around a 160x speedup.
MVV-LVA Move Ordering
To maximize the pruning efficiency itself, the moves are sorted before searching. The heuristic is MVV-LVA (Most Valuable Victim – Least Valuable Attacker): try capturing valuable pieces with cheap attackers first.
score = 100 + (victimValue × 10) – attackerValue
| Example | Formula | Score |
|---|---|---|
| Pawn captures Queen | 100 + (9×10) - 1 | 189 (highest) |
| Knight captures Queen | 100 + (9×10) - 3 | 187 |
| Pawn captures Pawn | 100 + (1×10) - 1 | 109 |
| No capture move | null | 0 (lowest) |
Quiescence Search
At leaf nodes (depth 0), a static evaluaton could be inaccurate if some capture is still possible (called the horizon effect). The quiescence search fixes this by continuing to search only capture moves until the position is stable:
function quiescence(alpha: number, beta: number, isMaximizing: boolean, qDepth = 0): number { nodeCount++; const standPat = evaluate(board); // if (isMaximizing) { if (standPat >= beta) return beta; // Already too good -> β cutoff if (standPat > alpha) alpha = standPat; // } if (qDepth >= 10) return standPat; // Hard depth limit const captures = orderMoves(generateCaptures(board, color), board); if (captures.length === 0) return standPat; // // search for only capture moves }
Real Time AI Thought Visualization
The main unique feature of this project was the visualization of the AI deliberation in real time. Essentially, the visualization of the algorithms and methods above. 4 different systems render the AI's thinking:
3D Arrows: I used cyan arrows for thinking, gold for the final decision. The worker indices are converted through rank inversion (7 - row) and the board centering (col - 3.5) to the 3D environment coordinates.
Ghost Pieces: A wireframe clone of the actual piece follows the deliberation coordinates and uses additive blending to look like it's a hologram
Narrative Logs: Each AI thought is translated into a plain text sentence with heuristic analysis: capture descriptions, center control commentary, and score based sentiment (aggressive/defensive).
Playback: Messages from the worker are shows at around 30 messages in under 100ms. A FIFO queue (aiVisualQueue) processes 1 thought every 800ms. But if the queue goes over 20 entries, the early thoughts are ignored to keep the visualization current and (real time)
setInterval(() => { if (aiVisualQueue.length > 0) { if (aiVisualQueue.length > 20) { const lastFew = aiVisualQueue.slice(aiVisualQueue.length - 5) aiVisualQueue.length = 0 aiVisualQueue.push(...lastFew) } const data = aiVisualQueue.shift() processAiEvent(data) } }, 800)
Some Challenges & Solutions
Challenge 1: The Horizon Effect in AI Evaluation
The Problem: The AI made some irrational moves → sacrificing pieces without benefit, or missing obvious captures → because the fixed depth 3 search evaluated positions mid capture exchange like they were final.
Cause: At depth 0, the original code returned a static evaluation. A position where White just captured a knight (but Black can recapture right after with a pawn) would be evaluated like if White permanently gained a knight
The Fix: Replaced the depth 0 static evaluation with a quiescence search that continues evaluating the capture only moves until the position stabilizes, with a hard depth cap of 10 in case of infinite chains.
Challenge 2: Main Thread Blocking During AI Search
The Problem: Early versions ran the minimax search on the main thread. The 3D scene froze for a couple seconds during the AI's turn → no camera rotation, no animations, no UI interaction.
The Fix: Moved the AI engine into a Web Worker. Vite bundles the worker using import.meta.url:
const aiWorker = new Worker(new URL('./chess-ai.worker.ts', import.meta.url), { type: 'module' })
The main thread right now sends the board state as a FEN string and gets the results asynchronously, which keeps the render loop at 60fps
Challenge 3: AI Visualization Overwhelming the UI
The Problem: The AI worker has around 30 thinking messages in under 100ms. Rendering every message immediately produced a meaningless flash of overlapping UI elements
The Fix: Implemented a FIFO queue that plays back 1 thought every 800ms. If the queue goes past 20 entries, the early thoughts are pruned and only the final 5 are kept, to make sure the visualization is visible and not overwhelming
Future Improvements
Modular Architecture
Currently: monolith.
Improvement: Change the monolith into focused modules: src/scene/ (Three.js setup), src/pieces/ (geometry factories), src/game/ (state management), src/rules/ (move generation), src/ai/ (worker integration), src/ui/ (overlays), src/input/ (raycaster, tap detection).
Impact: Better for unit testing, reduces the cognitive load, and makes the codebase more presentable at the file structure level.
Transposition Tables & Iterative Deepening
Currently: The AI re-evaluates identical board positions reached using different move orders. No caching.
Improvement: Add Zobrist hashing for board hashing, store results in a transposition table (Map<bigint, { score, depth, flag }>), and use iterative deepening (search depth 1, then 2, then 3... until a given time). Use each iteration's best move as the 1st candidate for the next.
Impact: Around a 2-4x search speed improvement, allowing for depth 5-6 in real time.
WebSocket-Based Multiplayer
Currently: Sandbox mode needs 2 people sharing one screen. There's already an Express server
Improvement: Add a WebSocket server with Express for room based matchmaking with shareable room codes.